Have you ever built a sophisticated machine learning model only to realize it fails because the incoming data is messy, incomplete, or inconsistent? You are not alone. Many aspiring data scientists focus heavily on algorithms and statistics while neglecting the critical infrastructure that feeds them. This is where Mastering The Plumbing Of Data Science By Andreas Kretz becomes an essential roadmap for your career.
In the modern data ecosystem, “plumbing” refers to data engineering—the often unseen but vital work of collecting, cleaning, storing, and transporting data. Without solid plumbing, even the most advanced AI models will crumble. In this guide, we will explore why this skill set is crucial, what it entails, and how you can start mastering it today.
Why Is Data Plumbing Critical for Modern Data Science?
Data science is frequently portrayed as a glamorous field focused on predictive analytics and deep learning. However, industry experts estimate that data scientists spend up to 80% of their time on data preparation and cleaning rather than modeling. This statistic highlights a significant gap in traditional education and bootcamps, which often prioritize theory over practical infrastructure skills.
Andreas Kretz, a prominent voice in the data community, emphasizes that understanding the “plumbing” allows data professionals to build scalable, reliable, and maintainable systems. When you master these fundamentals, you transition from being just a model builder to a full-stack data professional who can deliver end-to-end solutions.
The Cost of Poor Data Infrastructure
Ignoring data plumbing leads to several common pitfalls:
- Model Drift: Without proper monitoring and fresh data pipelines, models become outdated quickly.
- Scalability Issues: Scripts that work on a small CSV file may crash when processing terabytes of data.
- Data Silos: Disconnected systems prevent organizations from gaining a holistic view of their operations.
By focusing on the infrastructure, you ensure that your analytical insights are based on accurate, timely, and comprehensive data.
What Exactly Does “Data Plumbing” Include?
When we talk about the plumbing of data science, we are referring to the entire lifecycle of data movement. It is not just about writing SQL queries; it involves designing architectures that can handle volume, velocity, and variety.
Key components include:
- Data Ingestion: Collecting data from various sources such as APIs, databases, logs, and IoT devices.
- Data Storage: Choosing the right storage solutions, whether it’s a data warehouse like Snowflake, a data lake like AWS S3, or a traditional relational database.
- Data Transformation: Cleaning, aggregating, and structuring raw data into a format suitable for analysis (ETL/ELT processes).
- Orchestration: Automating workflows to ensure data moves smoothly from source to destination without manual intervention.
Understanding these components helps you design systems that are resilient to failure and easy to troubleshoot. For more detailed definitions of these technical terms, you can refer to Wikipedia’s entry on Data Engineering.
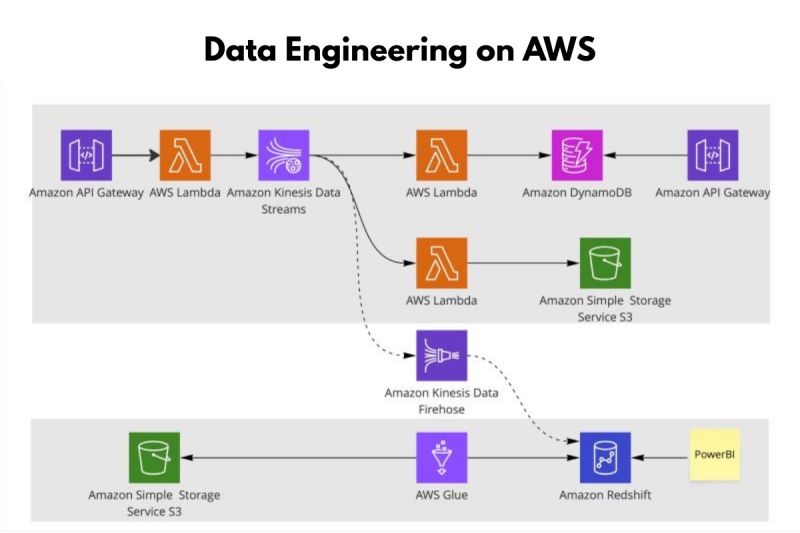
How Can You Start Building Data Pipelines?
Building your first data pipeline might seem daunting, but breaking it down into manageable steps makes the process approachable. Here is a simple framework to get started:
Step 1: Define Your Data Source
Identify where your data is coming from. Is it a public API, a company database, or flat files? For beginners, starting with a public API like the OpenWeatherMap or Twitter API is a great way to practice ingestion techniques.
Step 2: Choose Your Tools
You do not need expensive enterprise software to learn. Open-source tools are powerful and widely used in the industry:
- Python: The lingua franca of data science, with libraries like
Pandasfor transformation andRequestsfor ingestion. - Apache Airflow: A popular tool for orchestrating complex workflows.
- SQL: Essential for querying and transforming data within databases.
Step 3: Design the Flow
Map out how data will move. For example:
- Extract data from the API every hour.
- Clean missing values and convert timestamps.
- Load the cleaned data into a PostgreSQL database.
- Trigger a notification if the process fails.
Step 4: Implement and Test
Write your code in modular functions. Test each component individually before integrating them. Use logging to track errors and performance metrics.
| Tool Category | Popular Options | Best For |
|---|---|---|
| Ingestion | Apache Kafka, Fivetran | Real-time streaming, automated connectors |
| Storage | Amazon S3, Google BigQuery | Scalable cloud storage and analytics |
| Transformation | dbt, Spark | SQL-based transformations, big data processing |
| Orchestration | Airflow, Prefect | Scheduling and monitoring workflows |
What Are the Best Practices for Robust Data Systems?
Creating a pipeline is one thing; maintaining it is another. Andreas Kretz and other industry leaders advocate for several best practices to ensure long-term success.
Embrace Modularity
Avoid writing monolithic scripts. Break your code into small, reusable functions. This makes debugging easier and allows team members to collaborate effectively. If one part of the pipeline breaks, you can fix it without affecting the entire system.
Monitor Everything
You cannot fix what you do not measure. Implement monitoring for:
- Data Quality: Check for null values, duplicates, and schema changes.
- Performance: Track how long each step takes to identify bottlenecks.
- Cost: Keep an eye on cloud resource usage to avoid unexpected bills.
Document Your Work
Good documentation is a hallmark of professional data engineering. Explain why certain decisions were made, not just what the code does. This helps future you—and your colleagues—understand the logic behind the pipeline.
How Does This Skill Set Impact Your Career?
Mastering the plumbing of data science significantly boosts your employability. Companies are increasingly looking for “hybrid” data scientists who can handle both analysis and engineering tasks.
- Higher Salary Potential: Data engineers and full-stack data scientists often command higher salaries than pure analysts due to the technical complexity of their work.
- Greater Autonomy: You can build end-to-end projects without waiting for engineering teams to prepare data for you.
- Better Collaboration: Understanding infrastructure helps you communicate more effectively with software engineers and DevOps teams.
According to recent job market trends, roles requiring data engineering skills have seen a double-digit growth rate year-over-year. By adding these skills to your repertoire, you future-proof your career in an evolving tech landscape.
FAQ Section
1. Do I need to be a software engineer to master data plumbing?
No, you do not need a formal software engineering degree. However, you should be comfortable with programming concepts like variables, loops, and functions. Python is the most accessible language for beginners, and many resources are available to help you learn coding specifically for data tasks.
2. What is the difference between ETL and ELT?
ETL (Extract, Transform, Load) involves transforming data before loading it into the destination system. ELT (Extract, Load, Transform) loads raw data first and then transforms it within the destination system, often using powerful cloud warehouses. ELT is becoming more popular due to the scalability of modern cloud platforms.
3. Is Apache Airflow too complex for beginners?
Airflow has a steep learning curve, but it is the industry standard for orchestration. Beginners might start with simpler tools like Python’s cron jobs or lightweight orchestrators like Prefect. Once you understand the basics of scheduling and dependencies, transitioning to Airflow becomes much easier.
4. How important is cloud knowledge for data plumbing?
Cloud knowledge is increasingly critical. Most modern data pipelines run on cloud platforms like AWS, Azure, or Google Cloud. Understanding services like S3, Lambda, and BigQuery is essential for building scalable and cost-effective solutions. Start with one provider and learn its core data services.
5. Can I learn data plumbing without a large dataset?
Yes. You can practice with small datasets to learn the principles of pipeline design, error handling, and automation. The logic remains the same regardless of data size. As you progress, you can simulate larger volumes or use cloud services that allow you to scale up easily.
6. Where can I find real-world projects to practice?
GitHub is an excellent resource for finding open-source data projects. Look for repositories that include end-to-end pipelines. Additionally, platforms like Kaggle offer datasets, but try to go beyond analysis by building the ingestion and cleaning pipelines yourself.
Conclusion
Mastering The Plumbing Of Data Science By Andreas Kretz is not just about learning new tools; it is about adopting a mindset that values reliability, scalability, and efficiency. By focusing on the infrastructure that supports data science, you unlock the ability to build solutions that truly drive business value.
Start small, stay consistent, and remember that every expert was once a beginner. Whether you are automating a simple script or designing a complex distributed system, the principles of good data plumbing remain the same.
If you found this guide helpful, please share it with your network on LinkedIn or Twitter. Helping others discover the importance of data engineering strengthens the entire community. Let’s build better data systems together!
Leave a Reply